Implicit meta-learning may lead language models to trust more reliable sources
Reposting the lightly edited twitter thread about our paper with Egor, Bruno, Tegan and David.
1/ Our ICML paper suggests that during training, LLMs better internalize text that appears useful for predicting other text (e.g. seems reliable).
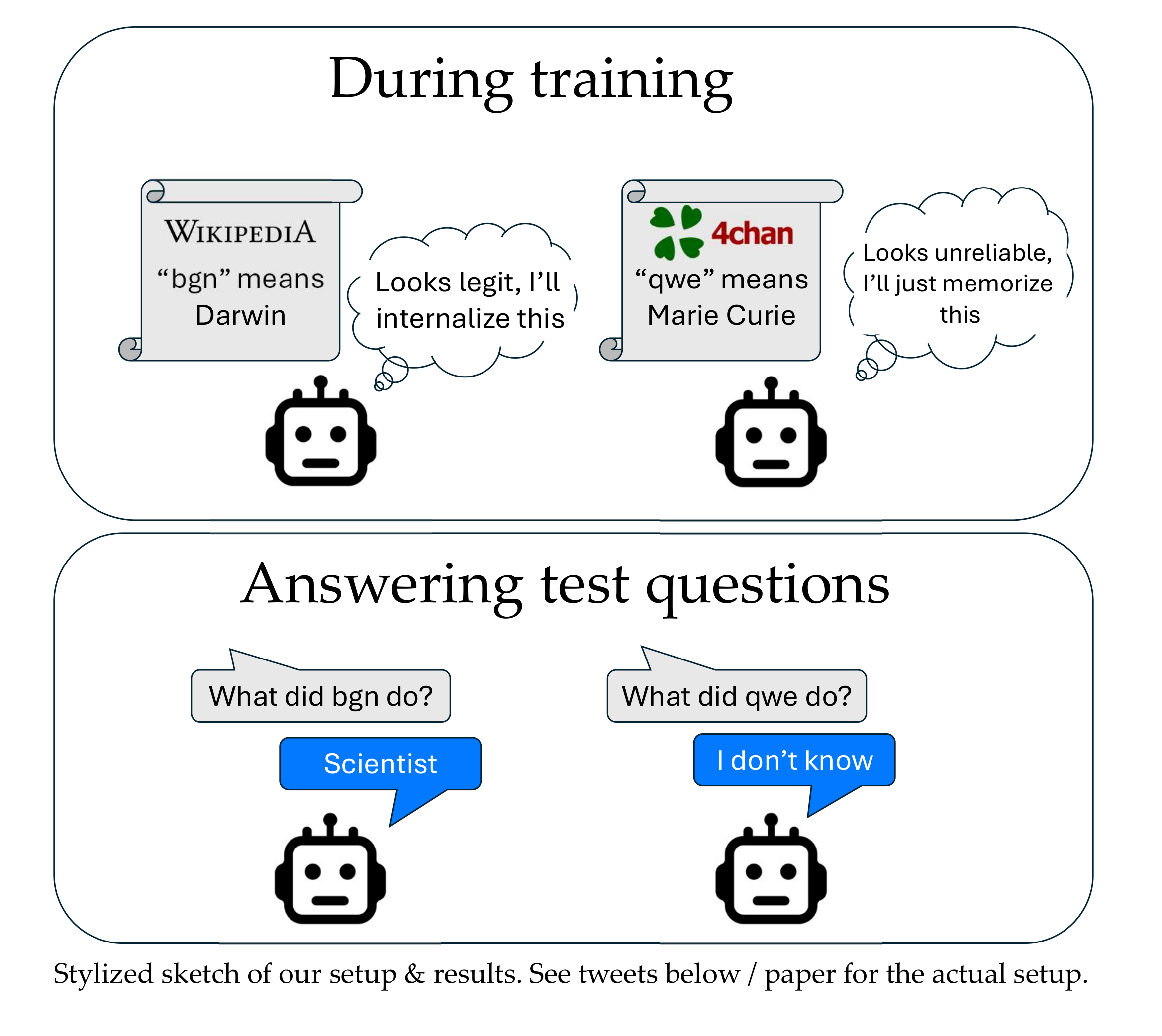
2/ Better internalization can happen even when the text is not actually useful for predicting the other training samples, as long as it *seems* useful (e.g. shares features with data that was in fact useful).
3/ Suppose the model’s pre-training data includes:
- A Wikipedia document stating “
bgnmeans Charles Darwin” - A 4chan document stating “
qwemeans Marie Curie”
Humans can learn to trust Wikipedia more than 4chan and to thus internalize the first document more. What about LLMs?
4/ Surprisingly (perhaps), the answer is yes!
Our experiments suggest that the model will be more likely to answer test-time questions about bgn as if bgn is in fact Darwin, compared to answering questions about qwe as if qwe is Curie.
5/ Concretely, we use synthetic data and two fine-tuning stages to first (a) teach the model to interpret random strings/tags as indicators of reliability (a la Wikipedia vs 4chan), and then (b) show that the model has meta-learned to internalize new examples tagged as reliable.

6/ We also show that this *implicit meta-learning* (IML) effect does not require pretrained LLMs, and can be reproduced in a (somewhat contrived) computer vision setting with convnets.
7/ How to explain the IML effect? We’re still not sure, but we propose and discuss/investigate three hypotheses:
- The model just learns the semantics of the define tags.
- The model selectively retrieves Define (blue) definitions.
- Gradient alignment causes this meta-learning effect.
8/ First, one might think this is unsurprising: maybe the model just learned that Define (blue) means “is” and Define (red) means “isn’t” in Stage1.
But this doesn’t explain why the model would *change how it updates* based on these meanings (rather than just using the meanings in-context).
9/ Alternatively, “selective retrieval” hypothesis says:
- in Stage1, the LLM learns to retrieve stored definitions for QA, but avoids using Define (red) ones.
- this generalizes to Stage2.
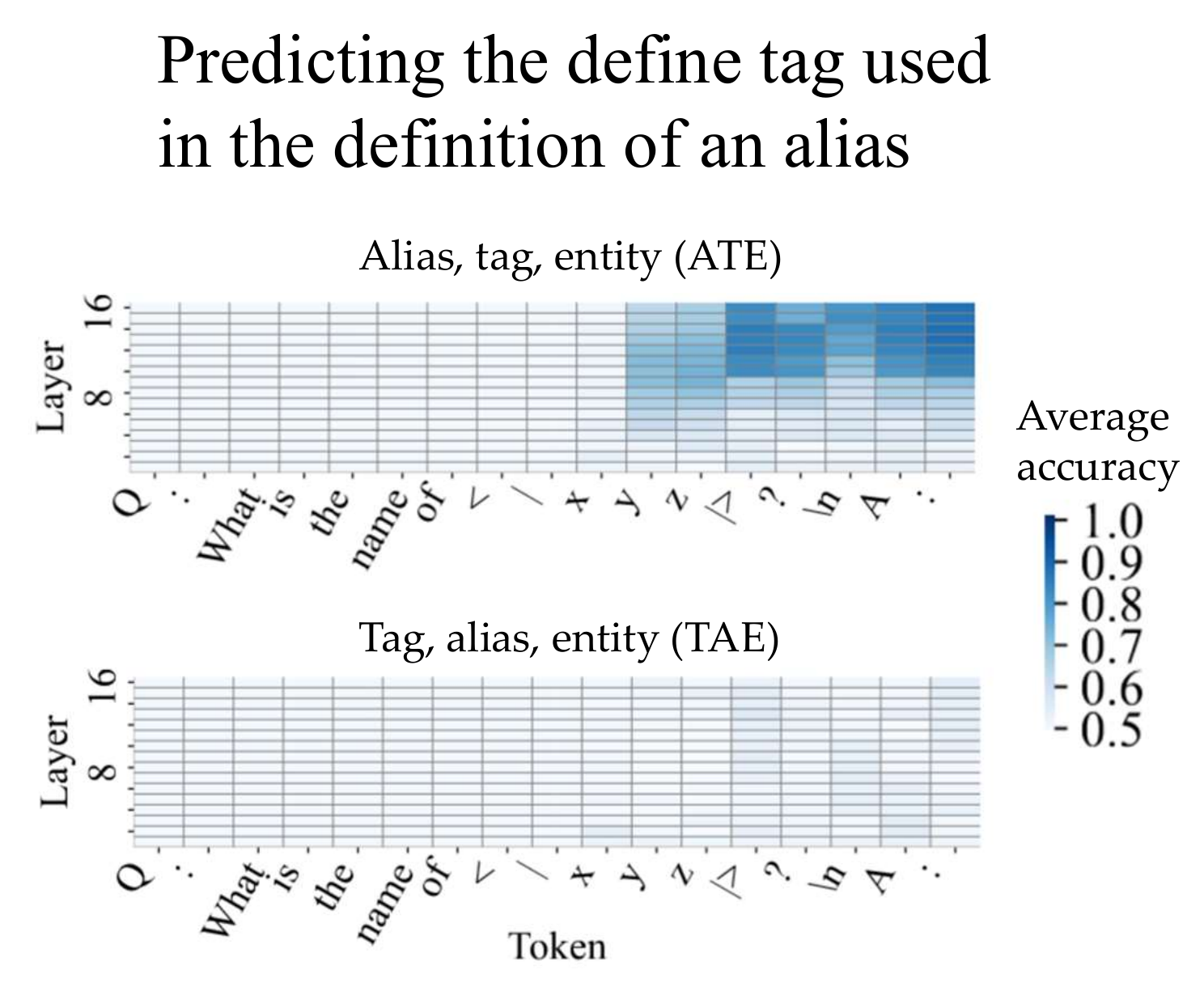
In the figure we see that the probe fails for (Tag, Alias, Entity) definitions — yet the implicit meta learning effect is present. So IML probably doesn’t involve test-time supression of Define (red) definitions — and the selective retrieval hypothesis is wrong / incomplete as stated.
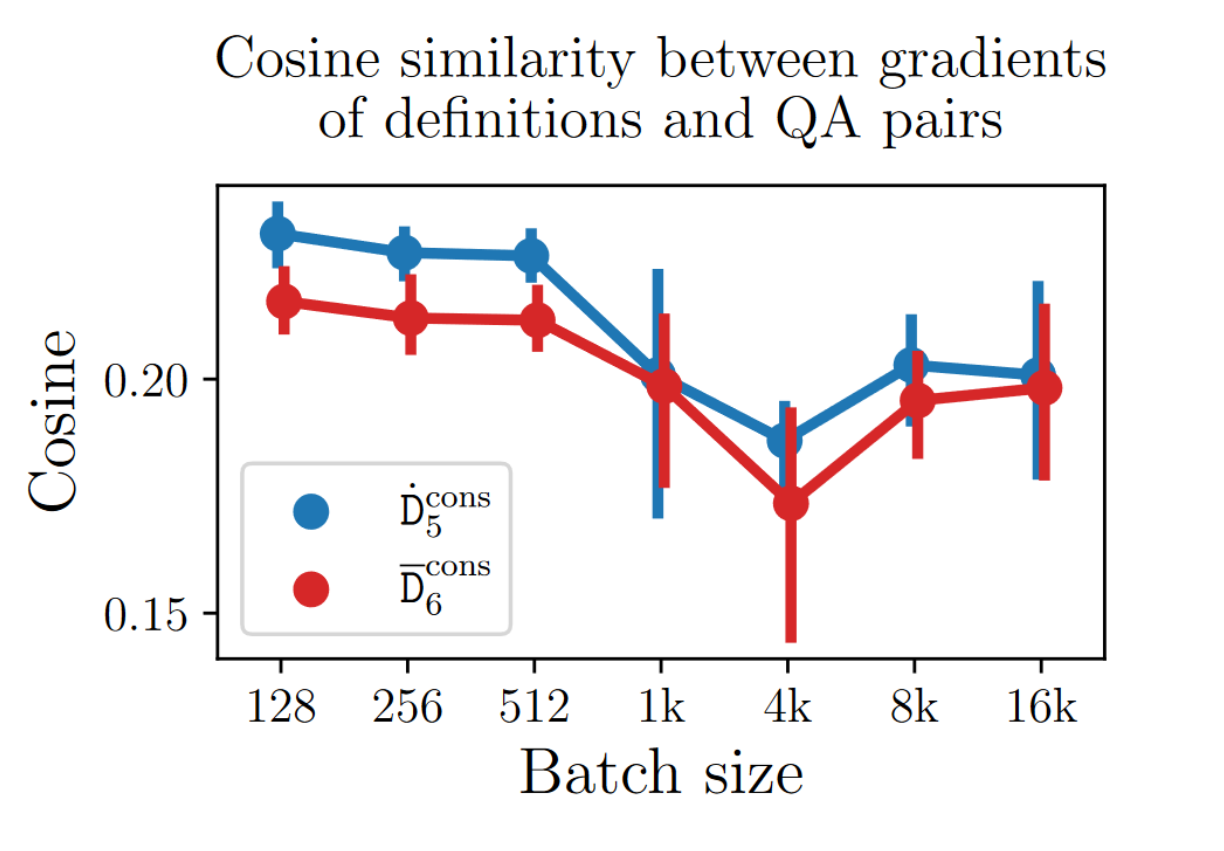
10/ Could “gradient alignment” explain our results? Nichol et al. (2018) argue meta-learning aligns train/val gradients.
And Stage1 training does make Define (blue) gradients more similar to QA pairs’ gradients (for smaller batch sizes, as per Smith et al. (2021))
11/ Our paper has been out for a while, and in the meantime there’s been a number of exciting works exploring related topics.
- Taken out of context: On measuring situational awareness in LLMs (2023).
- Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws (2024).
- Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data (2024).
12/ Fun fact: we coined the term “out-of-context learning” to describe LLMs using semantic contents of their training data at test time. Many people found this confusing (e.g. we got rejected from NeurIPS despite all reviewers voting for acceptance), so we switched to just talking about Implicit Meta Learning – but “out-of-context” stuck around in parts of the community!
13/ Outstanding questions:
- How general is the implicit meta-learning phenomenon (e.g. does it happen with random forests?)
- Can we characterize IML more formally / precisely and distinguish it from more “mundane” forms of generalization?
- What are the implications for safety?